Begin oktober heeft het AI-Team van OGD het resultaat van een Machine Learning proof of concept gepresenteerd bij Flanderijn, een incasso- en gerechtsdeurwaardersorganisatie. Flanderijn is een van de grootste gerechtsdeurwaarder organisaties in Nederland en onderscheidt zich door een aanpak die grotere schulden en onnodige kosten voor schuldenaren voorkomt. OGD en Flanderijn werken al jaren samen op het gebied van softwareontwikkeling. In september zijn we daarnaast begonnen met het testen van Machine Learning-toepassingen.
We hebben in 100 uur onderzocht of we konden voorspellen of een vordering betaald zou worden op het moment dat deze binnenkwam. Bij binnenkomst van de vordering is er meestal weinig informatie beschikbaar, waardoor het interessant was om hier Machine Learning op toe te passen.
Kunnen we met Machine Learning voorspellen of een vordering betaald wordt? Ja, dit is gelukt! Door het toepassen van Machine Learning konden we voor maar liefst 80% van de vorderingen correct voorspellen of deze betaald zou worden. Door het toepassen van deze oplossing is het mogelijk voor Flanderijn om meer nadruk te leggen op de achterliggende problemen en cliënten zo beter te ondersteunen. Benieuwd hoe we dit met ons AI-Team in slechts 100 uur hebben gedaan? In deze blog vertellen we meer over onze ervaringen met dit project.
Data-analyse
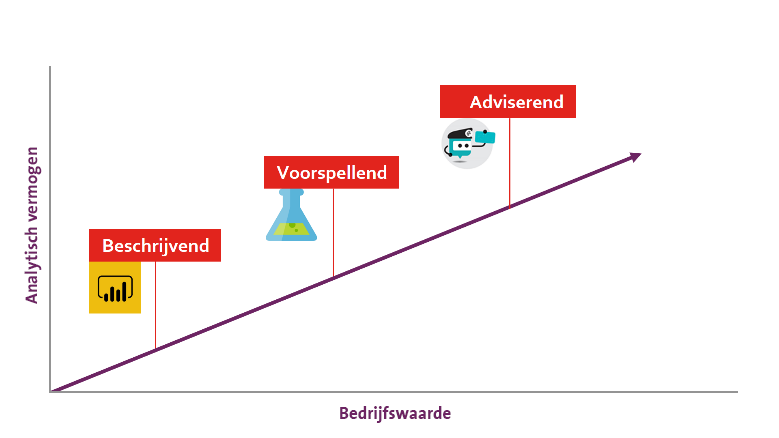
Hoewel Flanderijn veel bezig is met data-analyse, wil het bedrijf graag de volgende stap zetten; voorspellen in plaats van beschrijven. Net als veel andere bedrijven heeft Flanderijn beschikking over een enorme hoeveelheden data. Deze data geeft inzichten in rapportages waardoor deurwaarders een beter beeld krijgen over de lopende vorderingen. Waar eerst alleen de vraag ‘Wie betaalt?’ kon worden beantwoord, kan nu ook ‘Wie gaat betalen?’ worden beantwoord door gebruik te maken van Machine Learning. De complexiteit en de omvang van de data maakt Machine Learning dé techniek om goede voorspellingen mogelijk te maken.
Machine Learning
Bij traditionele softwareontwikkeling schrijf je de code en vervolgens voer je data in en dit zorgt voor de gewenste output. Machine Learning werkt net anders. Je combineert de input en gewenste output en laat een algoritme je code schrijven. Die code wordt voor het gemak daarna een model genoemd. Computers zijn in staat om voor grote hoeveelheden data heel precieze code oftewel modellen te schrijven. Zo is Machine Learning in staat om hele gerichte voorspellingen te doen waartoe mensen niet in staat zijn. Na het voorspellen is de volgende stap het bouwen van een adviserend systeem dat incassomedewerkers ondersteunt om het incassoproces positief te doorlopen. Niet alleen om de rekening betaald te krijgen, maar ook de klant te helpen zijn situatie te verbeteren.
Datascience proces
In het proof of concept hebben we een model gebouwd dat de volgende vraag beantwoord:
‘Gegeven een vordering, wat is de verwachting dat deze verhaald wordt?’ Om deze vraag te beantwoorden, hebben we het volgende plan van aanpak gebruikt:
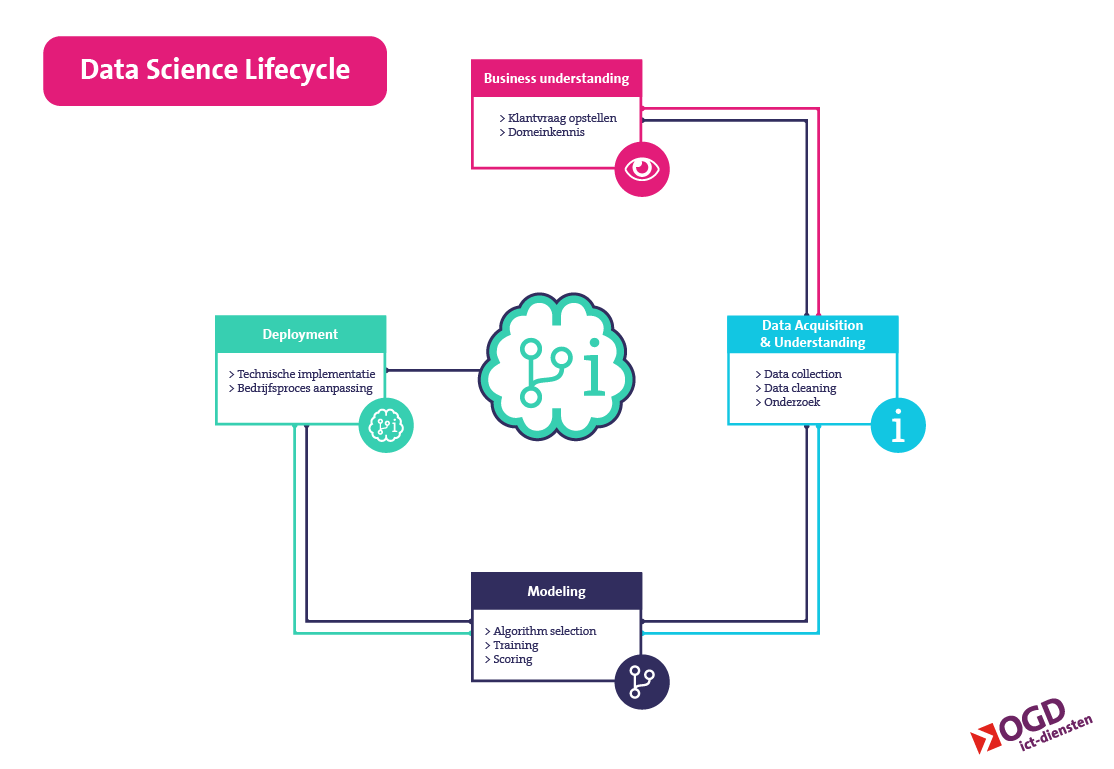
1. Domeinkennis
Om een zo goed mogelijk model te bouwen gebruiken we het bovenstaande datascience proces. Eerst willen we een idee hebben waarom je een vraag wilt beantwoorden en wat voor data je verwacht nodig te hebben. Ons doel was een model dat minstens 60% juist kon voorspellen. Als dit lukt, kunnen we aantonen dat er een verband bestaat tussen de beschikbare data en gemaakte voorspelling.
2. Datacollectie
De tweede stap is de benodigde data verzamelen en doorgronden. Vaak is het nodig om data op te schonen of te verwijderen als er fouten in zitten. Het kan zo zijn dat er stukken missen of dat bepaalde data de prestaties van het model niet verbeteren.
3. Modeleren
De laatste stap is het bouwen van het model zelf. We geven de computer alle input en bijbehorende output en specificeren welk soort model het moet worden. Het eerste model houden we zo simpel mogelijk en gebruiken we als baseline. Met het baselinemodel kunnen we eenvoudig de prestaties van complexere modellen of veranderingen aan de data beoordelen. Zo kunnen we het model gaan scherpstellen om de prestatie te verbeteren.
Resultaat
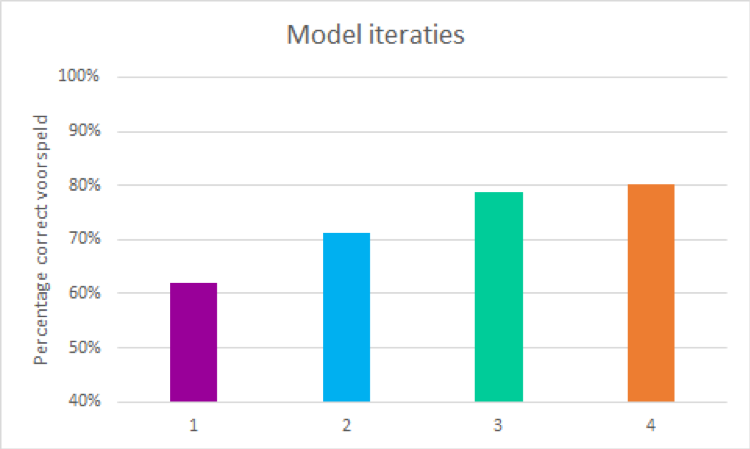
Ons baseline model gaf al een succesvolle voorspelling in 62% van de gevallen. We hebben het model vervolgens verbeterd door de stappen in het datascience proces te herhalen. We hebben de dataset bijvoorbeeld aangevuld met externe databronnen, maar er zijn ook delen van de dataset juist verwijderd. Uiteindelijk zorgde dit voor een model dat voor 80% van de vorderingen correct voorspelt of deze betaald zal worden.
Toepassingen
Het doel van het proof of concept is behaald. Met behulp van Machine Learning hebben we de stap kunnen zetten van het beschrijven van data naar het doen van voorspellingen. De waarde die een model toe kan voegen aan een bedrijf hangt af van de toepassing. Zowel de wensen van organisaties als de data zelf veranderen constant. Het is dan ook belangrijk om de voorspellingen te blijven monitoren en waar nodig het model aan te passen. Zo blijft Machine Learning je ondersteunen met vooruitstrevende inzichten.

Delen

Shift left: met gevoel voor richting

Ict-trends en -ontwikkelingen voor het mkb in 2018
