In mijn vorige blogpost heb ik in vogelvlucht de werking van machine learning besproken en zijn er een aantal praktische toepassingen voorbijgekomen. In deze post vertel ik u meer over de huidige toepassingen van machine learning bij OGD.
Machine learning bij OGD
Een belangrijke dienst van OGD is de Shared Servicedesk (SSD): de helpdesk waarmee veel van onze klanten contact opnemen wanneer ze te maken krijgen met ict-problemen. Om de kwaliteit van onze SSD te waarborgen maken we afspraken met onze klanten. Deze service level agreements (SLA’s) bepalen de maximale doorlooptijd van helpdesktickets en mogen niet worden overschreden. Een van de grootste uitdagingen hierbij is om de juiste bezetting voor de servicedesk te kiezen. De bezetting wordt nu nog vaak handmatig bepaald door experts, maar niet voor lang!
We werken momenteel aan een machine learning-model waarmee we de drukte op de SSD kunnen voorspellen. Zoals in de vorige blog genoemd zijn er twee belangrijke factoren die het succes van machine learning bepalen: de hoeveelheid beschikbare data en rekenkracht.
Samen met ons Business Intelligence-team krijgen we alle benodigde data boven water. Denk hierbij bijvoorbeeld aan het aantal binnengekomen tickets, maar ook aan de metadata over klanten die zijn aangesloten op onze servicedesk, zoals openingstijden en aantal medewerkers.
Vervolgens moet ook de rekenkracht geregeld worden. Hiervoor gebruikt OGD Microsoft Azure in combinatie met het machine learning-platform Cortana. Met Azure hebben we zelf in de hand hoeveel rekenkracht we beschikbaar hebben, doordat je gemakkelijk kunt op- en terugschalen met het aantal virtuele servers. Cortana maakt het daarbij erg gemakkelijk een model op te zetten en te trainen. Zo levert het getrainde model een voorspelling van het aantal te verwachten tickets in een tijdvak dat je zelf bepaalt, waarmee de gewenste bezetting bepaald kan worden.
 Cortana Intelligence Suite
Cortana Intelligence SuiteBounce bounce
Naast de voorspelling van het aantal tickets is er nog een ander probleem dat we oplossen met behulp van machine learning. We werken aan een model dat kan voorspellen hoe vaak een ticket zal verwisselen van behandelaar: ook wel bekend als het aantal bounces. Uit onze data blijkt dat een hoger aantal bounces zorgt voor een grotere kans op het overschrijden van de SLA. Met een goede voorspelling van het aantal bounces zijn deze risicovolle tickets beter in de gaten te houden en wordt het voor de behandelaars gemakkelijker om binnen de SLA te blijven.
Dit is direct een belangrijke beperking van machine learning die ik niet eerder heb besproken. Om machine learning succesvol te kunnen toepassen moet de dataset de gezochte relatie bevatten. Anders is het niet mogelijk om het model succesvol te trainen. Bij het bounce-project moeten we bijvoorbeeld testen of er binnen de data van een ticket een relatie te vinden is met het aantal bounces. Als na een aantal iteraties van het model het antwoord ‘nee’ blijkt te zijn, moeten we op zoek naar nieuwe data of bestaande data combineren tot de relatie wel zichtbaar wordt.
Machine learning in de toekomst
Naast de huidige projecten bij onze Shared Servicedesk werken we aan een aantal ideeën om de services van OGD te verbeteren en uit te breiden. Verschillende partijen bieden software om bots mee te bouwen: een interessant gebied om mee aan de slag te gaan. Bots kunnen bijvoorbeeld klanten ondersteunen door het eerste . Een bot kan in staat zijn om een aantal veelvoorkomende problemen direct op te lossen. Denk hierbij aan wachtwoordherstel of het opzoeken van simpele informatie. Om klanten beter van dienst te zijn heeft Expedia een aantal bots voor onder andere Facebook Messenger en Skype. De bots zijn in staat om simpele verzoeken van gebruikers uit te voeren zoals het zoeken en boeken van hotels.
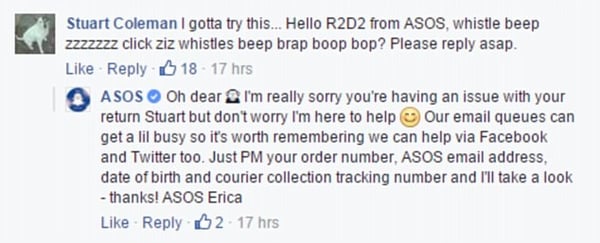 Bron: dailymail.co.uk
Bron: dailymail.co.ukDaarnaast kunnen meerdere bots ook samenwerken om grotere problemen te signaleren, zoals wanneer verschillende bots vaak dezelfde input krijgen. Dit helpt bij het trainen van de bots om de relatie te leren tussen vragen en de bijbehorende antwoorden. Een voorbeeld van hoe het niet moet is het algoritme achter de bots van ASOS op Facebook: die reageren op elke post alsof het om een klacht of probleem gaat. Daardoor ontstaan een aantal grappige situaties, maar is er uiteindelijk niemand mee geholpen.
Ik hoop dat u met veel plezier over machine learning heeft gelezen, en dat de kansen en mogelijkheden ervan u hebben geïnspireerd om de verdere ontwikkelingen in de gaten te houden. Mocht u meer willen weten, staan ik of mijn collega's u graag te woord in een vrijblijvend adviesgesprek.

Delen
Hoe machine learning jouw werk juist leuker maakt

Machine learning: hoe werkt het in de praktijk?
